Como Manter Personagens Consistentes em Vídeos NSFW com IA
Seus personagens de IA continuam mudando de rosto. Entenda por que — e como resolver.
O Problema Real: Seus Personagens Não Permanecem Iguais
Se você já passou algum tempo gerando conteúdo de vídeo NSFW com IA, quase certamente já experimentou isso: você cria um personagem que adora — o rosto perfeito, o tipo de corpo certo, exatamente o visual desejado. Aí tenta fazer um segundo vídeo com o mesmo personagem, e ela parece uma pessoa completamente diferente. Ou pior, o rosto começa a mudar no meio do vídeo, transformando-se em outra pessoa quadro a quadro.
Você não está sozinho. Esta é a reclamação mais comum em todas as comunidades de vídeo NSFW com IA — desde tópicos no Reddit até servidores do Discord e fóruns do Civitai. O problema não é que a IA não consiga gerar conteúdo atraente. Ela definitivamente consegue. O problema é que a IA não consegue lembrar quem é seu personagem.
Rosto Muda Entre Poses
Mude o ângulo, a expressão ou a pose, e a IA cria uma pessoa nova. O nariz fica mais largo, os olhos mudam de formato, o queixo se altera. É sutil o suficiente para parecer estranho e óbvio o suficiente para quebrar a imersão.
Detalhes Desaparecem Primeiro
Tatuagens, marcas de nascença, piercings, penteados específicos e acessórios são as primeiras vítimas. A IA os trata como decorações opcionais em vez de características de identidade. Um personagem com tatuagem no braço no quadro um pode ter braços limpos no quadro três.
Vídeos Mais Longos = Mais Desvio
Os primeiros 2-3 segundos geralmente ficam bons. Mas cada quadro adicional introduz pequenos erros que se acumulam. Aos 10 segundos, frequentemente você está olhando para uma parente do seu personagem original — não o personagem em si.
Prompts Sozinhos Não Resolvem
Não importa quão detalhado seu prompt de texto seja — "olhos verdes, rosto em formato de coração, nariz pequeno, cabelo castanho na altura dos ombros" — a IA interpreta tudo de novo a cada vez. Descrições textuais são inerentemente ambíguas. Duas gerações do mesmo prompt produzirão duas pessoas diferentes.
Por Que a IA Não Consegue Lembrar Seu Personagem
Antes de pular para as soluções, ajuda entender por que isso acontece. Não é um bug — é uma limitação fundamental de como os modelos de vídeo IA atuais funcionam.
A IA Não Tem Memória de Personagem
Quando você gera um novo vídeo NSFW com IA, o modelo começa do zero. Ele não tem o conceito de "esta é a mesma mulher da última vez." Cada geração é um evento independente. O modelo não armazena referência às suas saídas anteriores — simplesmente segue as instruções que você dá agora.
Prompts de Texto São Ambíguos
Descrever um rosto com palavras é como dar direções sem mapa. "Olhos azuis" pode significar mil tons e formatos diferentes. A IA preenche as lacunas de forma diferente a cada vez, por isso o mesmo prompt produz rostos diferentes.
Imagens de Referência São Frequentemente Ignoradas
Algumas plataformas e modelos aceitam imagens de referência, mas os resultados são inconsistentes. Testes da comunidade mostram que imagens de referência às vezes são parcialmente ignoradas, ou seguidas apenas vagamente — especialmente quando a pose ou ângulo muda significativamente.
Erro Cumulativo em Vídeo
Na geração de vídeo, cada quadro se baseia no anterior. Pequenos desvios acumulam com o tempo — como fotocopiar uma fotocópia. No centésimo quadro, a "cópia" parece visivelmente diferente do original.
Os Três Níveis de Consistência de Personagem
Consistência de personagem em vídeo NSFW com IA não é uma coisa — são três coisas empilhadas:
Identidade Visual
O básico: mesmo rosto, tipo de corpo, tom de pele, cor de cabelo e características distintivas entre quadros.
Consistência Editável
Você pode mudar a pose, roupa ou ângulo da câmera mantendo-o reconhecivelmente como a mesma pessoa? Isso é mais difícil do que parece.
Consistência Cross-Modal
O personagem tem a mesma aparência em diferentes tipos de saída — imagens estáticas, clipes curtos, vídeos mais longos? A maioria das ferramentas falha aqui.
Antes de Começar: A Ferramenta Que Você Vai Precisar
A maioria das soluções abaixo depende de uma ferramenta gratuita e de código aberto chamada ComfyUI. Se você nunca ouviu falar, aqui está o que precisa saber:
ComfyUI é um construtor visual de fluxos de trabalho de IA. Em vez de escrever código, você arrasta e solta diferentes módulos de IA — como blocos de montar — e os conecta. Por exemplo, pode encadear "carregar imagem" → "bloquear identidade facial" → "gerar vídeo" em um único pipeline.
Gratuito e Open Source
Sem taxas de assinatura, sem restrições de conteúdo. Você é dono de todo o fluxo de trabalho.
Roda Localmente
Tudo é processado no seu próprio computador. Seu conteúdo de vídeo NSFW com IA nunca toca em um servidor. Privacidade completa.
Infinitamente Flexível
Todas as ferramentas mencionadas neste guia — InstantID, LoRA, VACE, ReActor — existem como nós do ComfyUI que você pode combinar livremente.
Você precisará de um computador com GPU NVIDIA (mínimo 8GB VRAM, recomendado 12GB+). Sem GPU? Serviços em nuvem como RunPod e ThinkDiffusion permitem alugar uma por hora.
Como Instalar o ComfyUI no Seu Computador
Existem três formas de instalar o ComfyUI. Escolha a que for mais confortável para você:
Opção A: Aplicativo Desktop (Recomendado para Iniciantes)
A forma mais fácil. Acesse comfy.org, clique em Download e instale como qualquer aplicativo normal. Funciona no Windows e macOS. O instalador cuida do Python, PyTorch e CUDA automaticamente — você não precisa mexer no terminal. Depois de instalado, basta abrir o app e ele inicia o ComfyUI no seu navegador em http://127.0.0.1:8188.
Opção B: Versão Portátil (Apenas Windows)
Baixe o .zip portátil da página de releases do ComfyUI no GitHub. Extraia em qualquer lugar e execute o arquivo .bat incluído. Sem instalação — roda de forma independente com seu próprio Python. Bom para quem não quer instalar nada no sistema.
Opção C: Instalação Manual (Usuários Avançados)
Clone o repositório do GitHub, instale o Python 3.13, instale o PyTorch com suporte a CUDA, depois execute python main.py. Isso dá o máximo de controle, mas requer familiaridade com a linha de comando. Só escolha esta opção se souber o que está fazendo.
Requisitos de Hardware — Seja Honesto Com Sua GPU
O ComfyUI roda modelos de IA na sua placa de vídeo (GPU). Quanto mais VRAM sua GPU tiver, maiores e melhores modelos você pode rodar. Aqui está o que você precisa:
Mínimo (8GB VRAM)
GPUs como RTX 3060, RTX 4060. Você pode gerar imagens e vídeos curtos, mas precisará usar versões comprimidas (GGUF) dos modelos maiores. Funciona, mas é apertado.
Recomendado (12-16GB VRAM)
GPUs como RTX 3060 Ti (12GB), RTX 4070. Confortável para a maioria dos workflows deste guia. Você pode rodar InstantID, PuLID, treinamento de LoRA e modelos de vídeo padrão sem erros constantes de VRAM.
Ideal (24GB+ VRAM)
GPUs como RTX 3090, RTX 4090. Rode o modelo completo Wan 2.2 14B em 720p, treine LoRAs mais rápido e gere clipes de vídeo mais longos. O nível premium.
Sem GPU NVIDIA? Você pode rodar o ComfyUI em GPUs AMD (suporte experimental) ou Macs com Apple Silicon (M1/M2/M3/M4 via Metal), mas NVIDIA oferece a melhor compatibilidade e velocidade. Ou pule o hardware local com as opções de nuvem abaixo.
Sem GPU? Use o ComfyUI na Nuvem
Se seu computador não consegue rodar o ComfyUI localmente — ou você não quer lidar com hardware — vários serviços permitem rodar o ComfyUI em GPUs de nuvem alugadas. Você paga por hora e recebe um ambiente completo do ComfyUI no seu navegador, sem configuração necessária.
Comfy Cloud (Oficial)
Feito pela própria equipe do ComfyUI. Roda em poderosas GPUs RTX 6000 Pro (96GB VRAM). Plano gratuito: 400 créditos/mês (~35 vídeos curtos). Planos pagos: $20/mês (Standard), $35/mês (Creator — permite upload de LoRAs personalizados), $100/mês (Pro). Melhor para: quem quer a configuração mais simples possível com suporte oficial.
RunComfy
GPUs de nuvem pague-conforme-usa. Preços: $0,99/hr para 16GB VRAM (geração básica de imagens), $1,75/hr para 24GB VRAM (geração de vídeo), $2,50/hr para 48GB VRAM (modelos grandes). Plano Pro opcional a $19,99/mês com 20% de desconto em todas as taxas. 400+ modelos e nós pré-carregados. Melhor para: usuários avançados que querem escolher o nível da GPU.
ThinkDiffusion
Preços similares ao RunComfy: $0,99/hr (16GB), $1,75/hr (24GB), $2,50/hr (48GB). TD-Pro a $19,99/mês para descontos e 200GB de armazenamento persistente. Muitas extensões populares (incluindo ReActor) pré-instaladas. Melhor para: usuários que querem extensões pré-instaladas sem configuração.
Instalando Custom Nodes (Extensões)
O ComfyUI sozinho inclui apenas nós básicos. Para usar InstantID, PuLID, carregadores de LoRA, ReActor e tudo mais neste guia, você instala "custom nodes" (também chamados de extensões) — plugins feitos pela comunidade que adicionam novas funcionalidades.
ComfyUI V1 / Desktop App (Recomendado)
Boa notícia: se você está usando o ComfyUI V1 (o app Desktop ou uma build portátil recente), o gerenciador de extensões já vem integrado — você não precisa instalar nada extra. Basta clicar no ícone de Plugin / Extensões no canto superior direito da interface (ou acessar Menu → Help → Extension Management). De lá você pode pesquisar qualquer nó pelo nome — por exemplo, digite "InstantID" ou "PuLID" — clique em Install e reinicie o ComfyUI. Pronto.
Versões Antigas (Método Legado)
Se você está usando uma build mais antiga do ComfyUI que não possui o gerenciador integrado, pode instalá-lo manualmente: baixe o ComfyUI-Manager do GitHub e coloque a pasta no diretório ComfyUI/custom_nodes/. Reinicie o ComfyUI e você verá um botão "Manager" na barra de menu. Clique nele → "Custom Nodes Manager" → pesquise e instale nós da mesma forma.
Usuários de nuvem: Se você está usando RunComfy ou ThinkDiffusion, muitos nós populares (incluindo ReActor) já vêm pré-instalados. Você ainda pode instalar nós adicionais pelo gerenciador de extensões integrado da mesma forma.
5 Métodos Comprovados para Corrigir a Consistência de Personagens
Estas soluções estão ordenadas da mais simples à mais avançada. Você não precisa de todas as cinco — escolha as que correspondem ao seu nível e objetivos.
Método 1: Bloqueio de ID Zero-Shot
Mais Fácil — Sem TreinamentoO Que São Ferramentas de Bloqueio de ID?
Ferramentas como InstantID, PuLID e PhotoMaker são plugins para modelos de IA de imagem. Você fornece uma única foto de rosto, e elas extraem as características faciais chave — a distância entre os olhos, o formato do maxilar, o ângulo do nariz. Depois, ao gerar novas imagens, usam essas características como âncora para manter o rosto consistente.
O termo "zero-shot" significa que você não precisa treinar nada. Envie uma foto e a ferramenta funciona imediatamente. Sem espera, sem horas de GPU, sem preparação de dataset.
Como Se Comparam
Como Usar (Passo a Passo no ComfyUI)
Passo 1: Instalar o Nó
- Abra o ComfyUI. Se você está usando o ComfyUI V1 / Desktop, clique no ícone de Plugin / Extensões no canto superior direito (ou acesse Menu → Help → Extension Management). Em versões mais antigas, clique no botão Manager na barra de menu → Custom Nodes Manager.
- Na caixa de pesquisa, digite "ComfyUI_InstantID" (para InstantID) ou "PuLID_ComfyUI" (para PuLID). Clique em Install ao lado do resultado de "cubiq". Aguarde a conclusão e clique em Restart.
- Após o ComfyUI reiniciar, atualize seu navegador. Os novos nós agora estão disponíveis.
Passo 2: Baixar os Modelos Necessários
Os nós precisam de vários arquivos de modelo para funcionar. Veja onde colocar cada um:
Passo 3: Montar o Workflow
A forma mais fácil: vá à página do GitHub do InstantID ou PuLID, encontre a pasta examples/, baixe um arquivo de workflow .json de exemplo e arraste-o para a janela do ComfyUI no navegador. Ele carregará um workflow pré-montado com todos os nós já conectados. Depois basta:
- Selecione seu checkpoint SDXL no nó "Load Checkpoint"
- Carregue sua foto de referência no nó "Load Image"
- Escreva seu prompt na caixa "Positive Prompt" — descreva o que você quer (ex: "mulher bonita, perfil lateral, usando vestido preto elegante, iluminação de estúdio")
- Defina o CFG para 4-5 (importante! — InstantID funciona mal com o CFG padrão de 7-8, as imagens ficarão queimadas/com contraste excessivo)
- Use uma resolução como 1016x1016 em vez de 1024x1024 — isso evita marcas d'água dos dados de treinamento
- Clique em Queue Prompt (ou pressione Ctrl+Enter) para gerar
Dicas para Melhores Resultados
- Use uma foto de referência clara, bem iluminada e de frente. Referências de baixa qualidade produzem bloqueios de identidade de baixa qualidade.
- O método "Fidelity" do PuLID dá a correspondência facial mais próxima. "Style" dá mais liberdade criativa, mas menos semelhança. Comece com Fidelity.
- Se o rosto parecer "queimado" ou super-saturado, diminua o valor do CFG e/ou o peso do InstantID.
- Gere múltiplas imagens com seeds diferentes — escolha as melhores para sua folha de personagem.
O que pode fazer: Bloquear o rosto (características, formato, tom de pele) em múltiplas imagens geradas. Excelente para criar uma "folha de personagem" mostrando seu personagem de múltiplos ângulos.
O que não pode fazer: Bloquear o corpo inteiro. Roupas, tatuagens, proporções corporais e detalhes de penteado ainda variarão entre gerações. Esta é uma ferramenta facial, não uma ferramenta de personagem completo.
Método 2: Treinamento de LoRA de Personagem
Mais Confiável — Padrão da IndústriaO Que é um LoRA?
LoRA significa Low-Rank Adaptation. Em linguagem simples: é um pequeno "arquivo de memória" (tipicamente 20-80MB) que ensina um modelo de IA a reconhecer um personagem específico.
Pense no modelo de IA como um cérebro enorme que conhece milhões de rostos mas não conhece o seu personagem. Um LoRA é um complemento compacto que ensina esse cérebro uma identidade específica — rosto, tipo corporal, cabelo, tatuagens, características marcantes — tudo que torna seu personagem único.
Uma vez treinado, este arquivo LoRA se torna um "cartão de identidade do personagem" reutilizável. Toda vez que você gera conteúdo, carrega o LoRA e a IA sabe exatamente quem desenhar. Por isso o treinamento de LoRA é considerado o padrão-ouro para consistência de personagens em vídeo NSFW com IA.
O Que é uma Folha de Personagem?
Uma folha de personagem é uma coleção de 15-20 imagens mostrando o mesmo personagem de diferentes ângulos, expressões, poses e roupas — similar às folhas de referência usadas em animação profissional. Estas imagens se tornam o "livro didático" que ensina seu LoRA.
Como Fazer
- Monte seu dataset: Use o Método 1 (InstantID/PuLID) para gerar 15-20 imagens do seu personagem de diferentes ângulos e poses. Ou use ferramentas de edição baseadas em instrução como Qwen Image Edit.
- Curadoria de qualidade: Revise cada imagem cuidadosamente. Remova qualquer uma onde o personagem pareça diferente. Dados ruins de treinamento criam LoRAs ruins.
- Treine o LoRA: Use AI Toolkit (Ostris) ou Kohya_SS. Configurações: ~1.500-2.500 passos de treinamento, dimensão de rede 16. Em GPU de 12-16GB, leva cerca de 15-30 minutos.
- Aplique: Carregue seu LoRA treinado no ComfyUI ao gerar imagens ou vídeo NSFW com IA. Peso recomendado: 0.6-1.0. Alto demais causa artefatos; baixo demais não mantém a identidade.
Passo a Passo: Usando Seu LoRA no ComfyUI
Depois de treinar seu LoRA de personagem (você terá um arquivo .safetensors, tipicamente 20-80MB), veja exatamente como usá-lo no ComfyUI:
1. Adicionar o Arquivo LoRA
Copie seu arquivo .safetensors treinado para a pasta ComfyUI/models/loras/. Se o ComfyUI já estiver rodando, reinicie-o para que ele detecte o novo arquivo.
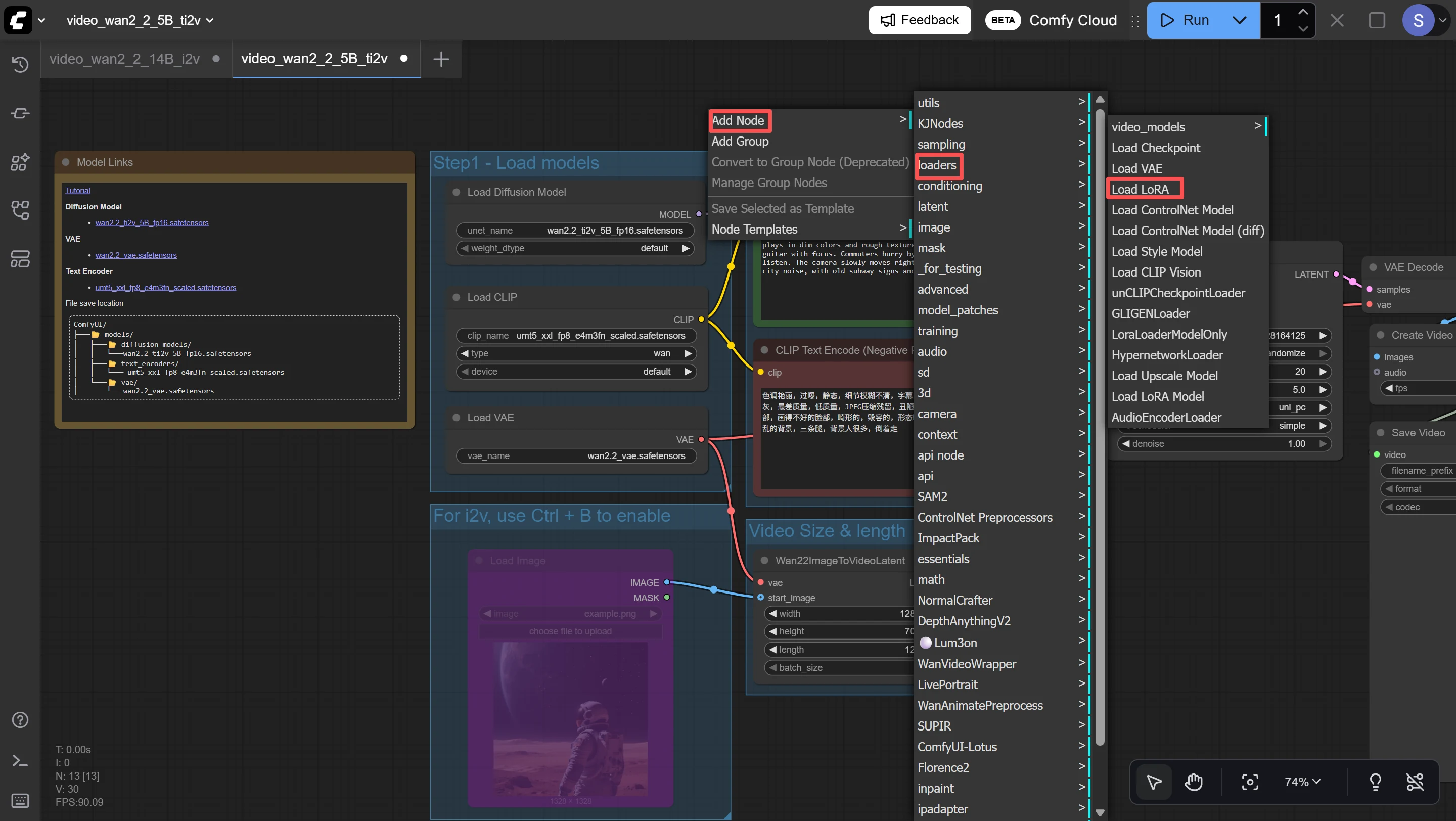
2. Adicionar o Nó Load LoRA
No ComfyUI, clique com o botão direito em qualquer lugar da tela → Add Node → loaders → Load LoRA. Um novo nó aparecerá com três configurações: lora_name, strength_model e strength_clip.
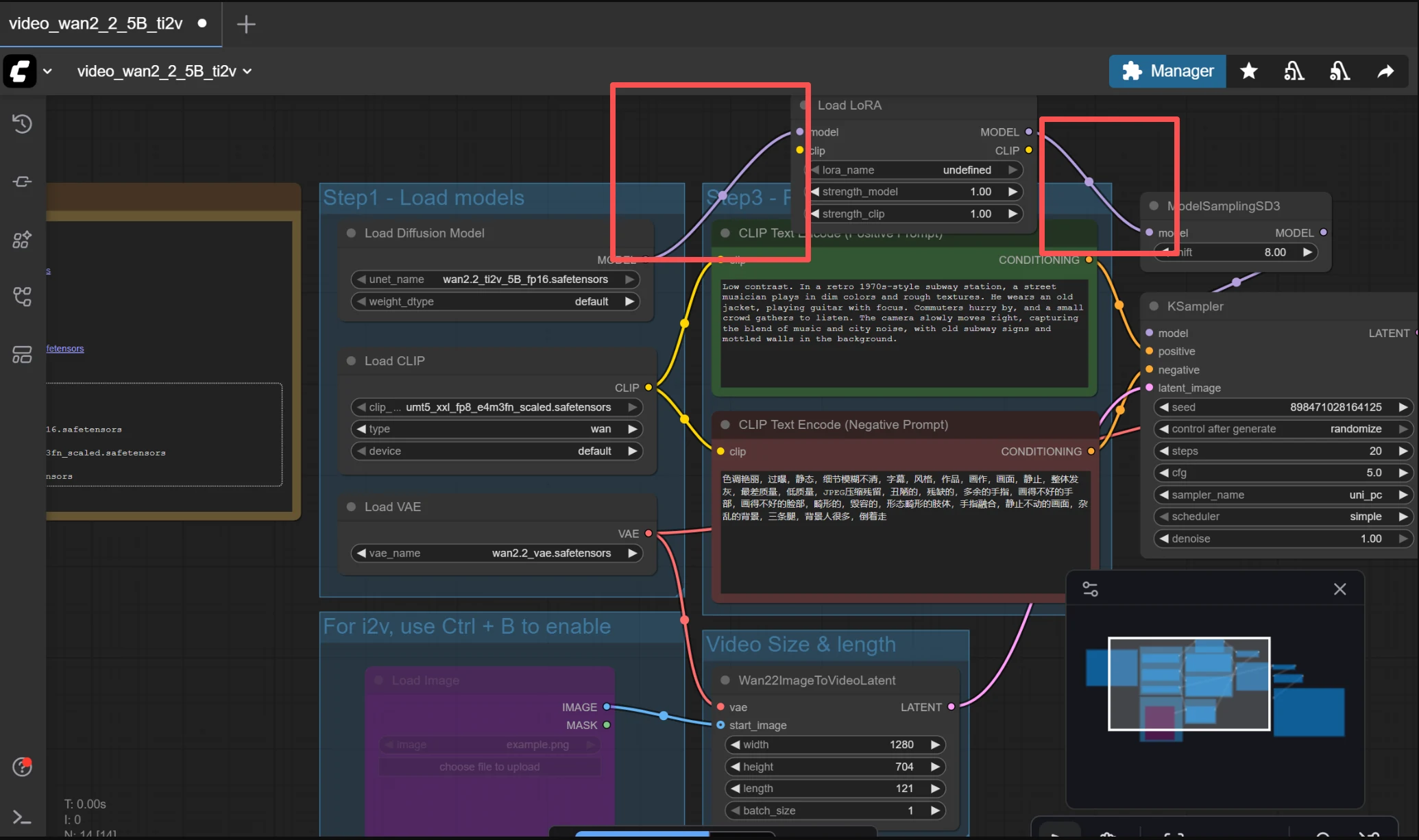
3. Conectar ao Seu Workflow
O nó Load LoRA vai entre o Checkpoint Loader e o KSampler. A cadeia é: Load Checkpoint → Load LoRA → KSampler. Conecte a saída MODEL do Checkpoint à entrada model do Load LoRA. Depois conecte as saídas MODEL e CLIP do Load LoRA aonde seu Checkpoint conectava antes (geralmente KSampler e seus nós de prompt).
4. Configurar as Opções
- lora_name: Clique no dropdown e selecione seu arquivo .safetensors da lista
- strength_model: Comece com 0.7. Isso controla o quão fortemente o LoRA influencia a imagem gerada. Maior = mais parecido com seu personagem, mas risco de artefatos. Menor = menos semelhança, mas visual mais natural.
- strength_clip: Comece com 0.7. Isso controla o quanto o LoRA influencia a interpretação do prompt de texto. Geralmente mantenha igual ao strength_model.
5. Usar a Palavra de Ativação
Quando você treinou o LoRA, provavelmente definiu uma "palavra de ativação" — uma palavra-chave que ativa o personagem (ex: "ohwx woman" ou "mychar"). Inclua esta palavra de ativação no seu prompt positivo junto com a descrição da cena. Por exemplo: "ohwx woman, standing on a balcony, sunset lighting, wearing white sundress".
Bônus: Empilhando Múltiplos LoRAs
Você pode encadear múltiplos nós Load LoRA em sequência — por exemplo, um para a identidade do personagem e outro para um estilo artístico específico. Basta conectá-los em série: Checkpoint → LoRA 1 → LoRA 2 → KSampler. Diminua a intensidade de cada um (0.4-0.6) ao empilhar para evitar conflitos.
O que pode fazer: Bloquear toda a identidade do personagem — rosto, penteado, tipo corporal, tatuagens, acessórios. Esta é a diferença chave do Método 1. Seu personagem se torna um ativo reutilizável consistente em centenas de gerações.
O que não pode fazer: Funcionar instantaneamente. Você precisa de 1-2 horas de preparação (criando datasets, treinando). Além disso, se suas imagens de treinamento forem inconsistentes, o LoRA aprenderá essas inconsistências.
Método 3: Geração de Vídeo Controlada
Melhor para Qualidade de VídeoPor Que Texto-para-Vídeo Puro Falha
Se você digitar "uma mulher caminhando na praia" em um gerador de texto-para-vídeo, a IA imagina uma mulher nova toda vez. Mesmo com um LoRA carregado, texto-para-vídeo puro dá liberdade criativa demais — e liberdade é inimiga da consistência. O insight chave: consistência é um problema de restrição, não de criatividade.
Os Modelos: Wan 2.2 & Wan 2.1 VACE
A série Wan da Alibaba é o padrão ouro atual para geração de vídeo IA open-source no ComfyUI. Duas versões são importantes:
Wan 2.2 (Recomendado)
Wan 2.2 é a versão open-source mais recente (licença Apache 2.0). Usa uma arquitetura Mixture-of-Experts (MoE) — 27 bilhões de parâmetros totais com 14 bilhões ativos por etapa de geração. Comparado ao Wan 2.1, foi treinado com 65% mais imagens e 83% mais dados de vídeo, resultando em coerência de movimento, estética e compreensão de prompts visivelmente melhores. Suporta Texto-para-Vídeo, Imagem-para-Vídeo, e roda nativamente no ComfyUI. A variante 5B (TI2V-5B) pode gerar vídeo 720p em uma única RTX 4090.
Como o Wan 2.2 é open-source e roda localmente na sua máquina, ele não possui a mesma moderação de conteúdo que serviços de API comercial aplicam. Suas gerações ficam no seu computador e não são filtradas por um servidor remoto. Dito isso, sempre use conteúdo gerado por IA de forma responsável e em conformidade com as leis locais.
Wan 2.1 VACE (Ainda Amplamente Usado)
VACE significa Video All-in-one Creation and Editing. Este modelo mais antigo continua popular porque muitos workflows e tutoriais existentes do ComfyUI são construídos em torno dele, e possui suporte maduro para modos Referência-para-Vídeo, Imagem-para-Vídeo e Vídeo de Controle. Se você encontrar um tutorial online que usa "Wan VACE", quase certamente é a versão 2.1. Ainda é uma escolha sólida, especialmente se sua GPU tem menos VRAM.
Referência-para-Vídeo
Você fornece uma imagem de referência do personagem, e o modelo a usa como âncora visual ao longo do vídeo. A IA referencia esta imagem para manter estilo, rosto e detalhes consistentes — mesmo quando o personagem se move ou o ângulo muda.
Imagem-para-Vídeo (I2V)
Você começa com uma imagem estática — talvez uma gerada com seu LoRA — e a anima. Como a aparência vem diretamente da imagem de entrada, a consistência é naturalmente preservada. Este é o caminho mais confiável para clipes curtos de vídeo NSFW com IA.
Vídeo de Controle
Você fornece um "vídeo esqueleto" — uma sequência de poses ou vídeo real mostrando o movimento desejado — e o modelo mapeia seu personagem nele. Imagine ter um vídeo de dança e substituir a dançarina pelo seu personagem mantendo cada movimento.
Como Usar
- Prepare uma imagem do personagem usando o Método 1 ou 2
- Carregue o modelo Wan 2.2 no ComfyUI (14B MoE recomendado para qualidade, 5B TI2V para usuários de RTX 4090). Ou carregue o Wan 2.1 VACE se seu workflow existente é construído em torno dele.
- Escolha seu modo: Referência-para-Vídeo se tiver referência de movimento, I2V se quiser apenas animar uma imagem
- Escreva um prompt simples descrevendo a ação + conecte sua imagem de referência → Gere
Dicas Importantes
- Combine a resolução da imagem de referência com a resolução de saída do vídeo — incompatibilidades causam perda de qualidade
- Comece com clipes curtos (2-5 segundos) para verificar a estabilidade do personagem antes de ir mais longo
- O modelo 14B requer 24GB+ VRAM. Se tiver menos, use versões quantizadas (GGUF) que rodam em 8-12GB. A variante 5B do Wan 2.2 é otimizada para GPUs de consumo.
- Se está começando do zero, vá com Wan 2.2. Se já tem um pipeline Wan 2.1 VACE funcionando com LoRAs treinados, avalie o custo de retreinamento antes de migrar.
Método 4: Costura de Tomadas Curtas
Melhor para Vídeos LongosPor Que Você Não Pode Gerar Vídeos Longos Diretamente
Os modelos de vídeo IA atuais acumulam erros ao longo do tempo. Os primeiros segundos ficam ótimos, mas cada quadro adicional introduz desvios pequenos. Após 10+ segundos, estes se acumulam em desvio de identidade visível. É como fotocopiar uma fotocópia: cada geração degrada o original.
O Que é First-Last Frame (FLF)?
FLF é elegantemente simples: você diz à IA "aqui está o quadro 1, e aqui está o quadro final — agora preencha o movimento entre eles." Como ambos os pontos estão travados, a IA tem muito menos espaço para desviar. É como conectar dois pontos com uma linha suave em vez de desenhar à mão livre.
O Fluxo de Trabalho
- Gere quadros-chave: Use seu LoRA de personagem + modelo de imagem para criar as imagens inicial e final de cada tomada. Planeje seu "storyboard" — o que acontece em cada segmento de 2-5 segundos.
- Gere cada clipe curto: Alimente cada par de quadros inicial/final no LTX 2.3 ou modo FLF do Wan 2.2. Cada clipe terá movimento suave e consistente.
- Costure os clipes: Use qualquer editor de vídeo (até gratuitos como DaVinci Resolve) para juntar seus clipes. Adicione transições entre segmentos.
- Retoque se necessário: Se algum clipe tiver desvio facial menor, aplique o Método 5 (reparo com face swap) para corrigir quadros específicos.
Por Que Este é o Padrão da Comunidade
Este método não é elegante, mas é a forma mais confiável de criar vídeo NSFW com IA mais longo com personagens consistentes. A comunidade convergiu nesta abordagem porque funciona: clipes curtos minimizam desvio, FLF trava os pontos extremos, e a costura dá controle total sobre ritmo e fluxo.
Método 5: Reparo com Face Swap
Correção FinalO Que é ReActor?
ReActor é um nó de troca de rosto para ComfyUI. Ele escaneia cada quadro do seu vídeo, detecta rostos e os substitui por um rosto alvo que você especifica. Também inclui restauração facial integrada (CodeFormer) que automaticamente melhora detalhes faciais.
Seu Papel no Fluxo de Trabalho
ReActor não é uma ferramenta de produção primária — é uma ferramenta de reparo. Use-o quando gerar um vídeo NSFW com IA usando os Métodos 2-4 e o resultado está 90% bom, mas alguns quadros têm desvio facial menor.
O que pode fazer: Corrigir desvio menor de identidade facial. Consertar quadros onde o nariz mudou levemente, a cor dos olhos alterou, ou o tom de pele desviou.
O que não pode fazer: Corrigir mudanças de corpo inteiro. Se o tipo corporal, roupa, penteado ou tatuagens mudaram, face swap não ajuda — opera apenas na região facial. Também tem dificuldade com perfis extremos e movimento rápido.
Como Usar
- Carregue o nó ReActor no ComfyUI
- Entrada: seu vídeo gerado + uma imagem facial clara de referência do personagem
- ReActor processa quadro a quadro, substituindo rostos + executando restauração CodeFormer
- Saída: o vídeo reparado com identidade facial consistente
O Fluxo de Trabalho Completo de 4 Camadas
Veja como todos os cinco métodos se encaixam em um pipeline pronto para produção de vídeo NSFW com IA com personagens consistentes:
Construção do Personagem
InstantID / PuLID
Vá de uma imagem a uma folha de personagem completa. Resolve: "Só tenho uma foto de referência."
Bloqueio do Personagem
Treinamento LoRA
Treine uma identidade de personagem reutilizável. Resolve: "Preciso deste personagem em muitos vídeos."
Geração de Vídeo
Wan 2.2 / VACE / FLF
Gere clipes de vídeo curtos e consistentes. Resolve: "O personagem desvia durante o vídeo."
Reparo
ReActor / CodeFormer
Corrija qualquer desvio facial restante. Resolve: "Alguns quadros estão levemente errados."
Você Não Precisa das Quatro Camadas
Se quer apenas algumas imagens consistentes → Camada 1 é suficiente. Para clipes curtos de vídeo NSFW com IA → Camadas 1 + 3. Para conteúdo serializado com personagem recorrente → todas as quatro camadas.
Ou... Pule Toda a Complexidade
O fluxo de trabalho acima é poderoso — mas sejamos honestos, requer ComfyUI, downloads de modelos, hardware GPU, treinamento LoRA e edição de vídeo. Se você quer criar conteúdo de vídeo NSFW com IA sem se tornar um engenheiro de workflow, existe um caminho mais simples.
deep-fake.ai: Uma Plataforma, Zero Configuração
deep-fake.ai foi construído especificamente para criadores que querem resultados sem overhead técnico. Em vez de fazer malabarismo com cinco ferramentas separadas, você tem tudo em um fluxo de trabalho unificado:
Suíte Criativa Unificada
Geração de imagem com IA, troca de rosto e criação de vídeo — tudo em uma plataforma. Sem troca de ferramentas, sem conversão de formatos. Vá da ideia ao vídeo NSFW com IA finalizado em minutos.
Verdadeiramente Sem Restrições
Sem filtros de conteúdo, sem roleta de moderação. deep-fake.ai foi projetado para conteúdo adulto desde o primeiro dia. O que você pede é o que você recebe.
Sem Hardware Necessário
Tudo roda na nuvem. Sem GPU NVIDIA, sem cálculos de VRAM, sem downloads de modelos. Funciona em qualquer dispositivo com navegador — incluindo seu celular.
Privacidade por Design
Todo conteúdo enviado é automaticamente deletado em uma hora. Zero logs, zero rastreamento. Você nem precisa criar uma conta para experimentar.
Perguntas Frequentes
Pronto para Criar Vídeos NSFW com IA Consistentes?
Seja escolhendo o fluxo completo do ComfyUI ou o caminho fácil com deep-fake.ai, personagens consistentes agora estão ao seu alcance. Comece a criar hoje.
Comece Grátis