









AlphaFace (2026)
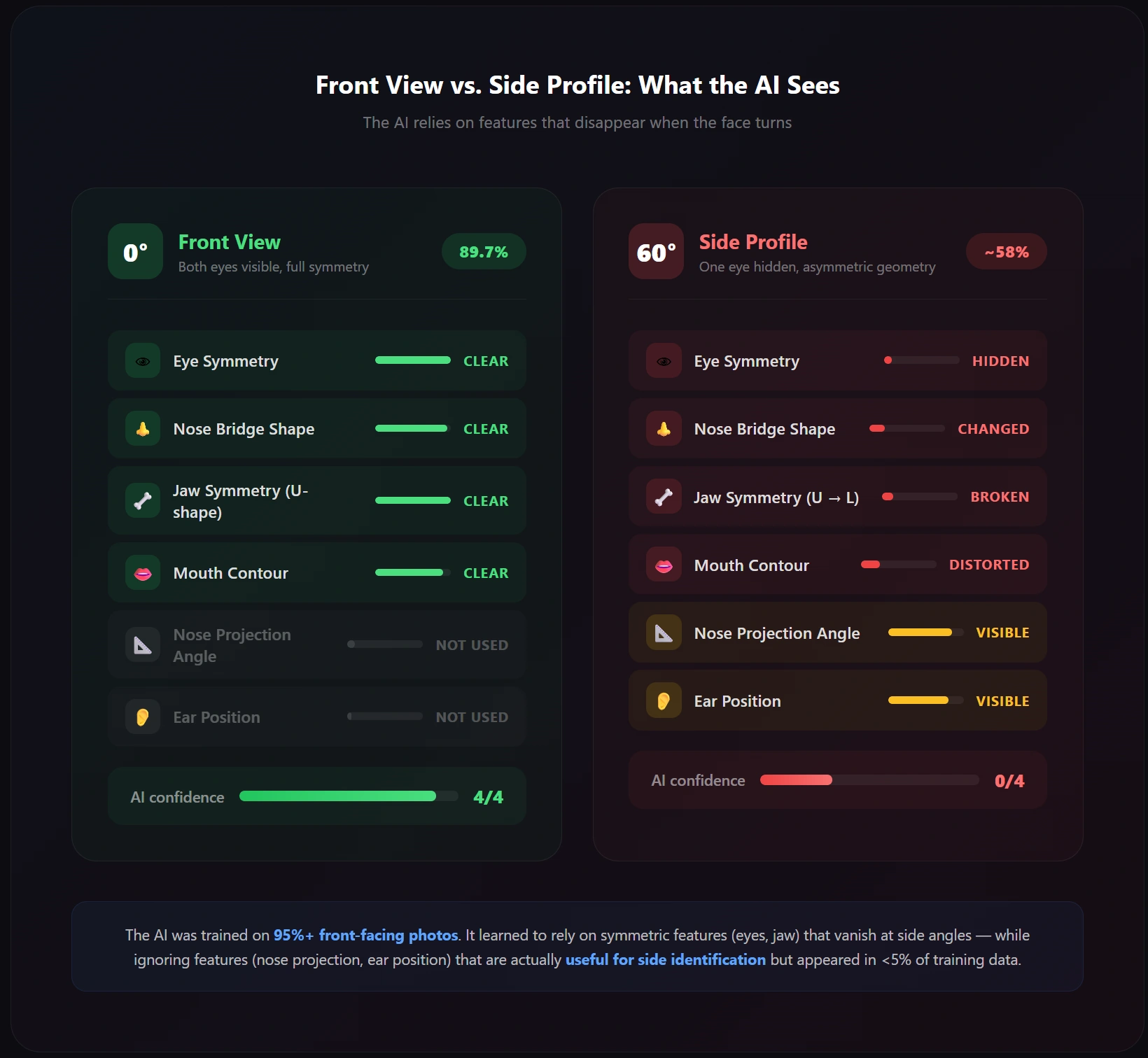
실시간 + 최고의 각도AlphaFace는 더 나은 3D 얼굴 모델을 구축하려는 구식 접근 방식을 버립니다. 대신, 비전-언어 모델(VLM)과 CLIP을 사용합니다 — AI 이미지 생성 뒤에 있는 동일한 기술 — 기하학적 수준이 아닌 개념적 수준에서 얼굴을 이해하기 위해.
이것이 평범한 언어로 의미하는 것: 3D 공간에서 코의 정확한 위치를 측정하려는 대신, AlphaFace는 '이것은 높은 광대뼈, 좁은 코, 아치형 눈썹을 가진 여성이다'를 이해합니다 — 그 설명은 카메라를 바라보든 옆으로 돌아서든 동일하게 유지됩니다.
41.5 FPS 실시간 속도 — 동급에서 가장 빠름. 포즈 오류가 이전 최고(FaceDancer)보다 극단적인 각도 데이터셋에서 17.4% 우수함.
영리한 트릭: CLIP은 훈련 중에만 사용됩니다. 런타임에서는 모델이 그것 없이 실행되어 추론을 실시간 비디오에 충분히 빠르게 유지합니다.