









AlphaFace (2026)
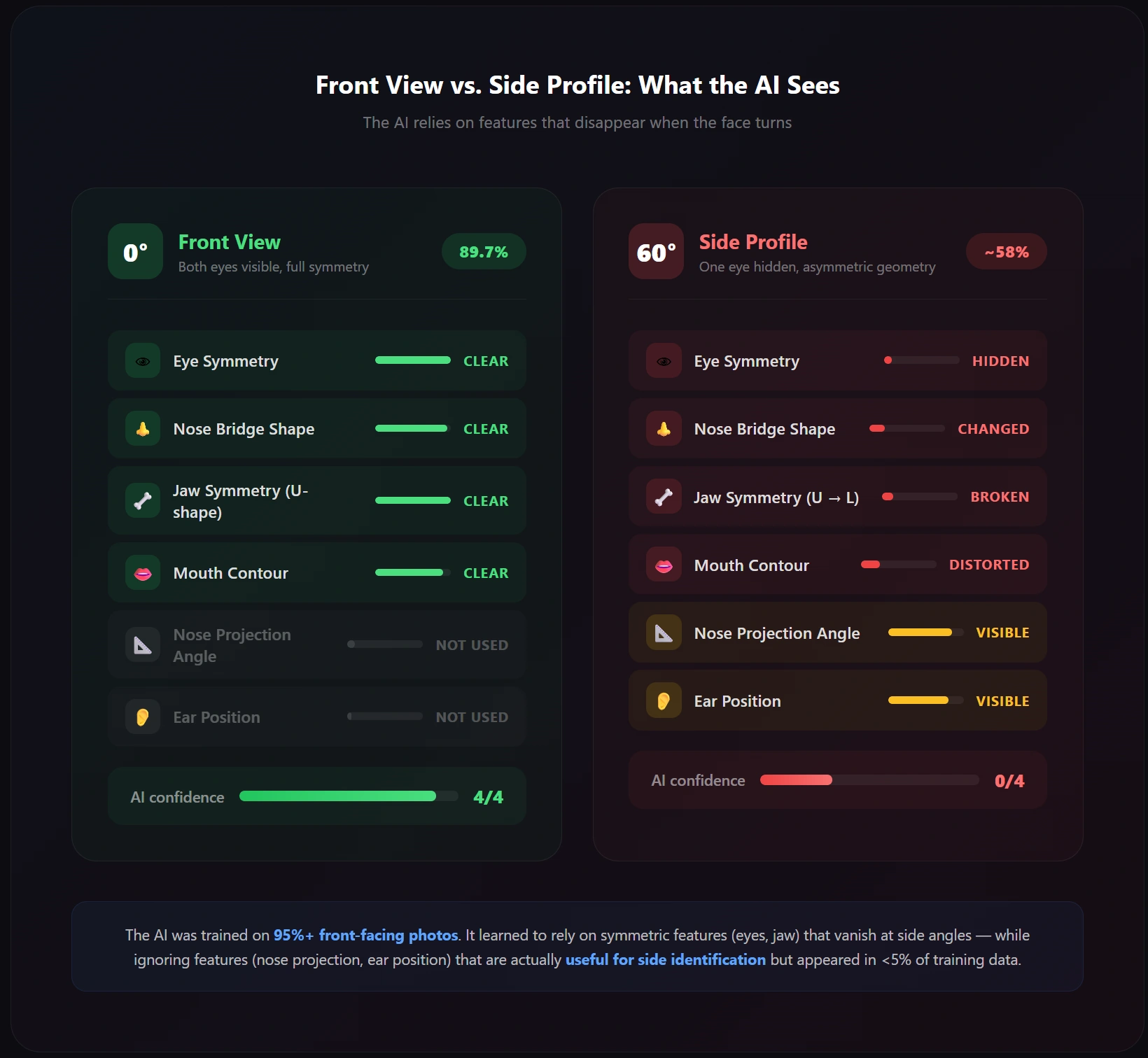
Real-Time + Best AnglesAlphaFace throws out the old approach of trying to build better 3D face models. Instead, it uses a Vision-Language Model (VLM) and CLIP — the same technology behind AI image generation — to understand faces at a conceptual level rather than a geometric one.
What this means in plain language: instead of trying to measure the exact position of your nose in 3D space, AlphaFace understands that "this is a woman with high cheekbones, a narrow nose, and arched eyebrows" — and that description stays the same whether you're facing the camera or turned sideways.
41.5 FPS real-time speed — fastest in its class. Pose error 17.4% better than the previous best (FaceDancer) on extreme angle datasets.
The clever trick: CLIP is only used during training. At runtime, the model runs without it, keeping inference fast enough for real-time video.